

コンフルエントはdata in motion=ストリームデータを活用させるプラットフォームを提供する企業です。IPO目論見書S-1をまとめました。
本記事は情報の整理を目的としており、投資・その他の行動を勧誘する目的で作成したものではございません。投資の判断はご自身の意思と決定でお願いします。本記事の内容は主にIPO目論見書S-1をもとに作成していますが、翻訳における誤りや、具体的解釈の内容についての保証は致しかねます。
- コンフルエント NASDAQ:CFLT IPO目論見書 S-1まとめ
- 日本での取り扱い証券会社:(SBI証券・楽天証券・マネックス証券)
- 上場予定日はいつ?株価は? コンフルエントのIPO公募価格、上場初値は?(公開価格29ドル-33ドル) (上場初値:44ドル)上場市場:NASDAQ 上場日:2021年6月24日
- 引受幹事企業:モルガンスタンレーなど
- 経営者:ジェイ・クレプス Apache Kafkaのオリジナルクリエイター
- 売上・利益
- 何をしている会社?→リアルタイムのデータを分析するストリーム処理を行う企業。
- 市場機会
- 商品・サービス
- 顧客
- 収益モデル
- 競合:Microsoft、Amazon、Google、Tibco software、Cloudera、IBM 、Oracleなど
- リスク要因 Risk factor
- 決算
コンフルエント NASDAQ:CFLT IPO目論見書 S-1まとめ
- 企業に必要なのは、生成されるデータに基づいてリアルタイムにビジネスを行うための戦略と基盤となるデータプラットフォームです。この「data in motion=動いているデータ」という考え方は、少なくとも「静止しているデータ」と同様に企業の運営にとって重要であり、新世代の勝ち組企業は、このデータに基づいて行動できるかどうかで決まると考えています。
- Confluentは、data in motionを世界中のすべての企業の「中枢神経系」とすることができる製品を作るために設立されました。
- 2021年1-3月 売上7,700万ドル(前年5,090万ドル +51%)サブスクリプションによる売り上げは全売上の88%
- ARR 10万ドル以上の顧客560社
日本での取り扱い証券会社:(SBI証券・楽天証券・マネックス証券)
SBI証券(8/12~取扱)
楽天証券(7/21~取扱)
マネックス証券(6/24~取扱)
DMM 株 (DMMドットコム証券)(不明)
リンクから口座開設できます。
必ずしもすべての証券会社が気になる銘柄を取り扱うわけでは無いです。複数の口座を持っておくことで、心配は減ります。
上場予定日はいつ?株価は? コンフルエントのIPO公募価格、上場初値は?(公開価格29ドル-33ドル) (上場初値:44ドル)上場市場:NASDAQ 上場日:2021年6月24日
44ドルで開け、45.02ドルでクローズしました。
引受幹事企業:モルガンスタンレーなど
- モルガンスタンレー
- JPモルガン
- ゴールドマンサックス
- バンクオブアメリカセキュリティズ
- シティグループ
- バークレーズ
- クレディスイス
- ドイチェバンク
- UBS
- ウエルズファーゴ
などです
経営者:ジェイ・クレプス Apache Kafkaのオリジナルクリエイター
ジェイ・クレプス 41歳
- 2014年9月の設立~最高経営責任者(CEO)
- 2009年7月~2014年9月 LinkedInでエンジニア、エンジニアリングマネージャー、ソフトウェアアーキテクト
- LinkedInではApache Kafka(後述)のオリジナルクリエイター
- カリフォルニア大学サンタクルーズ校でコンピュータサイエンスの学士号とコンピュータサイエンスの修士号を取得
ステファン トムリンソン
- 2020年6月~最高財務責任者
- 2019年4月~2020年6月アルファベット社のグーグルLLCでグーグルクラウドと技術インフラの最高財務責任者
- 2012年2月~2018年3月まで、サイバーセキュリティ企業であるパロアルトネットワークス株式会社のエグゼクティブバイスプレジデント兼最高財務責任者
- 以前は、クラウドネットワーキングソリューションのプロバイダーであるアリスタネットワークス社の最高財務責任者、民間投資会社シルバーレイククラフトワークのパートナー兼最高管理責任者、インテリジェントワイヤレスLANスイッチングシステムのプロバイダーであるアルバネットワークス社の最高財務責任者を務める
- トリニティ・カレッジで社会学の学士号、サンタクララ大学で修士号.B A.を取得
エリカ・シュルツ
- 2019年10月~フィールドオペレーション担当プレジデント
- 2018年4月~2019年10月 クラウドベースのオブザーバビリティソフトウェア企業であるNew Relic, Inc.で最高収益責任者、2017年4月~2018年4月までセールス&カスタマーサクセス担当エグゼクティブバイスプレジデント、2015年8月~2017年4月までコマーシャル&エンタープライズ担当エグゼクティブバイスプレジデント、2014年6月~2015年8月までグローバルエンタープライズセールス担当シニアバイスプレジデントを務める
- 2012年2月~2014年3月 デジタル・エンゲージメント企業であるLivePerson, Inc.のグローバル・セールス&カスタマー・サクセス担当エグゼクティブ・バイスプレジデント
- 1995年11月から2012年1月までは、コンピュータ・テクノロジー企業であるOracle Corporation
- ダートマス大学でスペイン語とラテンアメリカ研究の学士号を取得しており、同大学では評議員会の副議長も務める
売上・利益

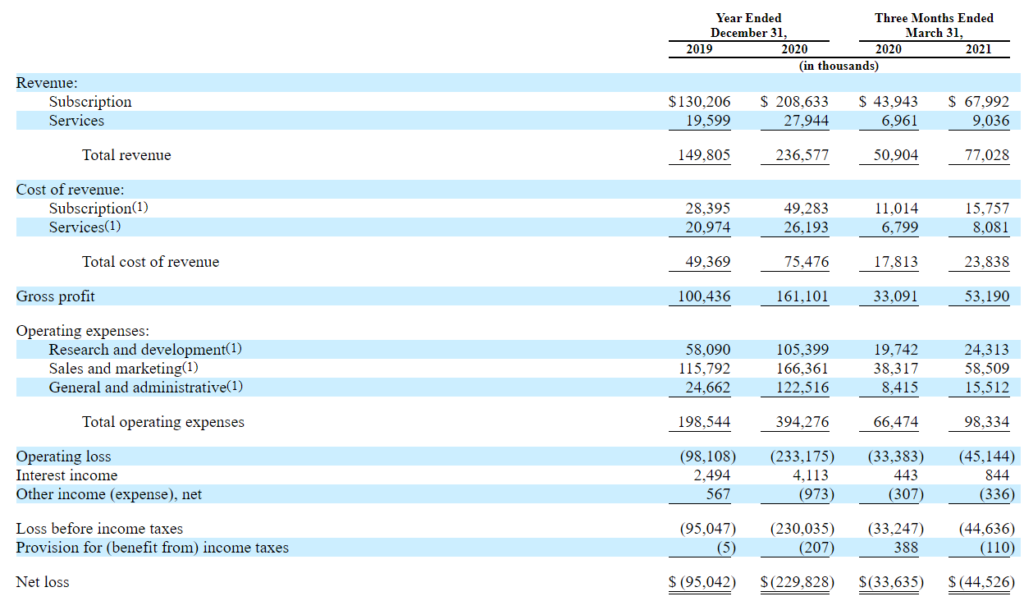
2020年度売上:
2億3660万ドル(前年1億4980万ドル+58%)
2021年1~3月売上:
7700万ドル(前年5090万ドル +51%)サブスクリプションによる売り上げは全売上の88%
Confluent Cloud売上:
2020年 3,140万ドル(前年1,440万ドル +117%)従量制の契約。
Confluent Platform売上:
2020年 1億7,720万ドル(前年1億1,580万ドル +53%)
2021年1~3月:5,410万ドル(前年3,770万ドル+43%)
米国外からの収益:2021年1~3月全体の36%(前年は34%)
2020年営業損失:2億3,320万ドル(前年9,810万ドル)
2020年純損失:2億2,980万ドル(前年9,500万ドル)
2021年1~3月営業損失4,510万ドル(前年3,340万ドル)
2021年1~3月純損失4,450万ドル(3,360万ドル)
2020年12月31日時点累積赤字:4億610万ドルおよび2021年3月31日時点累積赤字:4億5,060万ドル
GP率はおよそ80%程度です。
NRR(ドルベースの純保持率)2019年12月末時点:134%、2020年12月末時点:125%、2021年3月末時点:117%です。
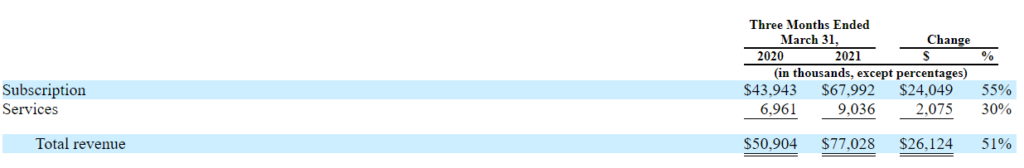
サブスクリプション売り上げが年度で見ると+55%の成長をしていて、全体の成長は+51%です。
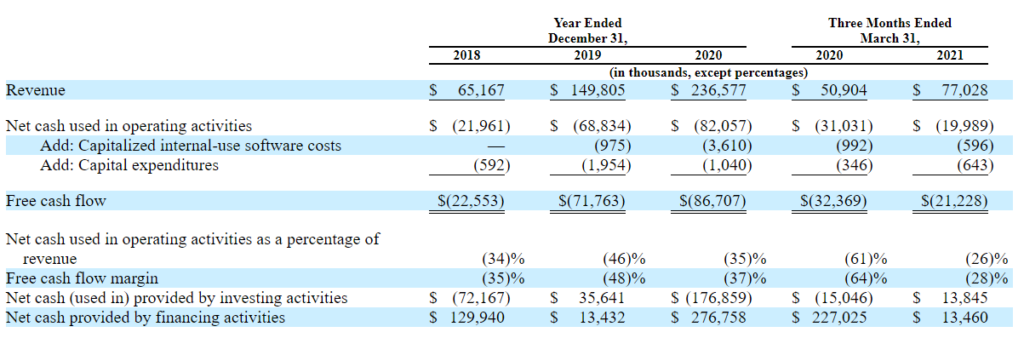
2021年1-3月 営業キャッシュフローマージンは-26%です。
何をしている会社?→リアルタイムのデータを分析するストリーム処理を行う企業。
リアルタイムのストリームデータ(data in motion)を分析するプラットフォームを提供する企業です。
※S-1を見ただけで技術的な部分の理解が困難だったので他の記事を多数引用して説明します。
例えば、LinkedInの場合、毎日3,000億ものメッセージを処理している。Uberは、常時何千もの乗客と運転手をマッチングしている。Ciscoの場合は、何千もの交差点やそこを通過する車両の動向を解析している。
これらの企業は皆「ストリーム」を用いて、データ処理を行っている。この情報処理技術を用いれば、大量のフローデータの中で、関係するものだけをリアルタイムで処理可能だ。例えばNetflixではログイン直後にユーザーの利用履歴から、好みの映画をリコメンドしてくれる。
この技術の基となったオープンソーステクノロジー「Apache Kafka」は、LinkedIn出身のチームから生み出された。Confluent社は現在18名の社員を抱え、カリフォルニア州サニーベールに本拠を置く。既にLinkedInをはじめUberやCisco、Goldman Sachsといった大手企業にKafkaを提供し、彼らのデータ処理の考え方を変革しようとしている。
「ストリームデータ処理は、事業を根幹から変えるかもしれない。データ処理の重要性はどんどん増しているんだ」とCEOのJay Krepsは言う。
ビッグデータ処理で30億円を調達 Netflixを支えるConfluent社の野望 | Forbes JAPAN(フォーブス ジャパン)
Confluent PlatformはApache Kafkaを中心としたプラットフォームです。Apache Kafkaについては、別の記事で紹介しているため、詳しくはそちらを併せてご覧ください。Apache Kafkaは、とても優れたオープンソースのソフトウェアではありますが、実際に使用してみると、特に商用利用時においては、機能の不足などで困ることもあります。
Confluent PlatformはLinkedInのプロジェクトで、Apache Kafkaの開発に最初に携わった主要メンバーによって創設されたConfluent社が提供しています。複数のシステムやあらゆる場所からのデータを企業の中央のConfluent Platformに統合することにより、リアルタイムのデータパイプラインとリアルタイム アプリケーションを簡単に構築できるようになります。さまざまなシステム間の連携、データ転送において煩わしいインターフェースプログラムの開発やファイルのインポート/エクスポートから解放され、企業はデータからビジネス価値を引き出すことだけに集中できます。
Confluent Platform 技術ガイド データの可能性を無限に追及する Confluent Platformとは (networld.co.jp)
従来のデータベース技術は、data in motion(以下、「ストリームデータ」と略します。)のために設計されたものではなく、保存されている静止データのために設計されたものでした。
従来のデータベースや最新のデータベース(NoSQL、時系列、グラフデータベースなど)は、拡張性や分析速度が大幅に向上していますが、これらのデータベースは、データが静止している状態のユースケースに限定されており、ストリームデータを利用することはできません。
ストリームデータを扱う代表的なオープンソースであるApache Kafkaは、2011年にLinkedInの創業者たちによって開発され、データ処理の新たなパラダイムを主流にしました。しかし、これは始まりに過ぎませんでした。Confluentは、ストリームデータを世界中のすべての企業の中枢神経系にすることができる製品を作るために設立されました。
Apache Kafkaは、ストリームデータの業界標準となっています。Apache Kafkaは、最も成功したオープンソースプロジェクトの一つであり、Fortune 500(社)の70%以上で使用されていると推定されています。
最新のアプリケーションは、Apache Kafkaと統合することが求められており、Kafkaのための技術的なスキルセットは、業界において重要な要件となっています。
Confluentの製品は、Apache Kafkaの機能を提供しますが、それをクラウド用に構築されたプラットフォーム上で行い、大企業との接続性を補完し、大規模な処理と統治の能力を備えています。開発者コミュニティは、ストリームデータのための完全なプラットフォームの利点を理解しています。そのため、お客様のエンジニアリング部門やIT部門のソフトウェア開発者は、コンフルエントの基本的な技術や価値提案を熟知しており、コンフルエントに代わって情報を提供してくれます。
ビジネスSNSの大手、LinkedInのオープンソースのフレームワークです。
大規模なストリームデータを扱うことができるオープンソースの分散メッセージングシステム。
Apache kafkaとは (nttdata.com)
Kafkaはシステムにおいてストリームデータの中継役を担います。ストリームデータとは継続的/連続的に生成されるデータの集合のことです。機器の動作情報/APサーバのログ/ECサイトの購入情報/SNSの投稿など様々なデータをストリームデータとして扱うことができます。
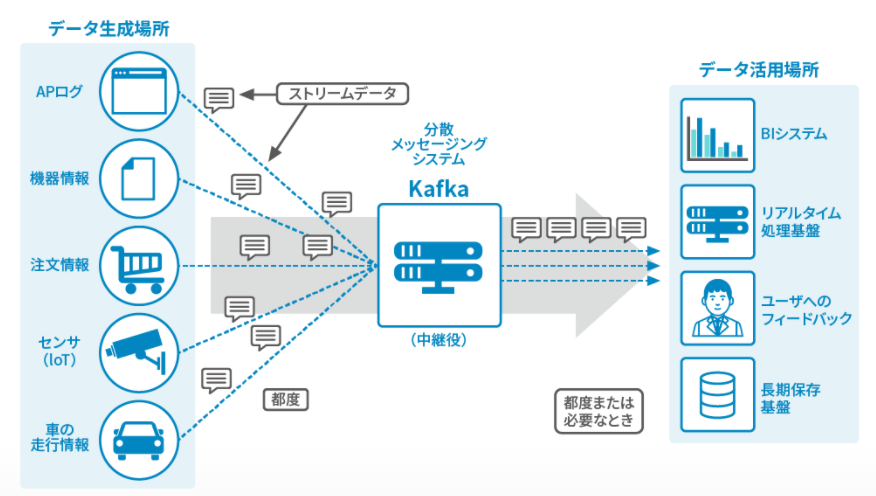
ストリームデータを扱うことで得られるメリット
小売業においては、複数のチャネルで正確な在庫追跡を行い、消費者が実際に店頭に並んでいる商品の最新情報を把握できるようにするのか、それとも、在庫があると思っていた商品が品切れで、消費者をがっかりさせてしまうのかの違いです。
製造業においては、モノのインターネット(IoT)センサーからのリアルタイムのデータを活用して予知保全を行い、ダウンタイムを削減するのか、それとも人の手で機器を点検するのかという違いがあります。
市場機会
リアルタイムデータに基づくリッチでパーソナライズされた体験が新たな課題に。
生活のほぼすべての側面がデジタル化される中、企業や消費者は、デジタル体験が高度に利用可能で、応答性が高く、パーソナライズされていることを期待しています。これまでは、昨日のデータに基づいてビジネスを行うことで十分に成功してきました。今日では、お客様の要求に応えられなかったり、現在のビジネスデータの統合が数分でも遅れると、お客様の不満やビジネスリスクにつながります。
IoTがユビキタスになる。
IoTと接続されたセンサーの増加は、世界中で生成されるデータ量の急激な増加の重要な要因となっています。接続されたIoTデバイスから生成されるデータは、2025年までに73.1ゼタバイトになると予測されており、これは2019年に生成された18.3ゼタバイトの約4倍にあたります。この膨大な量のリアルタイムデータを取得し、変革をもたらすソリューションを構築するためには、企業は、動き回るデータに対応した新しい基礎データインフラストラクチャが必要です。
企業はクラウドファーストやマルチクラウドに対応するために、インフラの近代化を急速に進めている。
IDCによると、世界のパブリッククラウドサービス市場は、2020年から2024年にかけて、それぞれ2,920億ドルから6,280億ドルに増加すると予想されています。最近のGartner社のクラウド導入調査によると、75%以上の企業がマルチクラウド導入モデルを採用しています。企業は、クラウド導入の道のりでベンダーロックを避けるために、マルチクラウド戦略を採用すると考えられます。
クラウドへの移行は始まったばかりで、世界は今後もハイブリッド化していく。
IDCによると、世界のクラウドコンピューティング市場が急速に成長しているにもかかわらず、過去5年間でシステム・インフラ・ソフトウェア支出のうち、パブリック・クラウド・サービスからの支出は17%にとどまっています。多くの企業では、引き続き大規模なオンプレミスのデプロイメントが行われています。その結果、一部のデータはオンプレミスやプライベートクラウドに保存され、残りのデータは様々なパブリッククラウドに分散され、データはそれらの間を行き来するという、二分化されたデータストレージ環境になっています。
従来のデータインフラはストリームデータに対応していない
アプリケーションを構築して展開する際の従来のアプローチは、アプリケーションとデータベースを組み合わせてデータを保存し、それをアプリケーションが定期的に取得するというものでした。
このようなデータベース中心のアプローチは、データウェアハウスやリレーショナルデータベース、NoSQLデータベースでよく見られます。データベースは、データストレージの伝統から生まれました。データベースは、保存されたデータのリポジトリを管理し、アプリケーションが必要に応じてその時点のデータセットにクエリーでアクセスできるようにします。つまり、データベースはデータを管理するためのプラットフォームなのです。データベースには数え切れないほどの種類があり、年間消費額が940億ドルを超えるカテゴリーを構成していますが、すべてのデータベースは「データの保存」というパラダイムに根ざしており、その結果生じる制限を共有しています。
商品・サービス
たとえば、小売業においては、複数のチャネルで正確な在庫追跡を行い、消費者が実際に店頭に並んでいる商品の最新のスナップショットを確実に入手できるようにすることで在庫切れを防いだり、製造業においては、IoTセンサーから得られるリアルタイムのデータを活用して予知保全を行い、ダウンタイムを削減するなどが出来ます。
CONFLUENT S-1/A より
- confluent platform
- confluent cloud
を提供しています。
confluent platformについては、以下のリンクに記載しています。
エンタープライズのためのデータ・イン・モーションプラットフォーム | Confluent
一言で言うとApache Kafkaをより使いやすくするためのプラットフォームです。
オンプレミス・クラウドの両方に対応可能です。
アプリケーションをオンプレミスまたはプライベートクラウドに置いているお客様は、そのデータセンターでConfluent Platformを使用します。オンプレミスとクラウドの両方、あるいは複数のクラウドをお持ちのお客様は、それぞれの環境でConfluentをご利用いただきます。これらのソリューションを組み合わせることで、これらすべてのお客様の環境をつなぐデータストリームのための1つの統一されたファブリックとして機能します。
CONFLUENT S-1/A より
confluent cloudは
AWS(アマゾンウェブサービス)などのクラウドサービス上でKafkaベースのソリューションを実行するためのソフトウェアです。
Confluent Cloudは、KafkaベースのソリューションをAmazon Web Services上にデプロイ可能にするSaaSソリューションだ。そのロードマップには、GoogleおよびMicrosoft Cloudとのインテグレーションも入っている。Confluent CloudはSaaSとして、Kafkaの最新安定バージョンを用意し、開発者になじみのある同じオープンソースAPI、パフォーマンスAWSにおける複数アベイラビリティゾーン、JavaやPython、C/C++、.NET、Goによるクライアントサポートを提供する。利用可能なスループットは、読み込み負荷で1-10MBps、書き込み負荷でその半分となり、データシートに書かれているように購入プランによって違いがある。
Confluent Cloud、Apache KafkaをSaaSとして提供 (infoq.com)
confluentのソリューションには、3つの差別化要素があります。
クラウドネイティブ。Confluentは、ストリームデータに対して真のクラウド機能を提供します。Confluentは、大規模な拡張性、弾力性、安全性、グローバルな相互接続性を備えた、完全に管理されたクラウド・ネイティブなサービスを提供し、アジャイルな開発を可能にします。これは、オンプレミスのソフトウェアを単にクラウドの仮想マシンで提供する場合とは全く異なる体験です。Confluentを利用することで、開発者も企業も、データインフラの管理という運用上のオーバーヘッドを気にすることなく、アプリケーションに集中して価値を高めることができます」と述べています。
完全な。Confluentは、オープンソースのApache Kafkaの機能とCoufuluent独自の重要な機能を活用することで、ストリームデータのための完全なプラットフォームを構築しました。当社の技術は、データの移動と処理を同時に行います。ストリームデータのネイティブデータベースであるksqlDBなどの特定のツールを使用することで、ユーザーはわずか数個のSQLステートメントを使用してデータインモーションアプリケーションを構築することができ、100以上のコネクタも備えています。
あらゆる場所で。 私たちは、真にハイブリッドでマルチクラウドなサービスを構築しました。お客様のクラウドやマルチクラウド環境、オンプレミス、またはその両方を組み合わせてサポートすることができます。お客様が効果的にデジタルトランスフォーメーションを行うためには、テクノロジー環境全体をシームレスに統合できる、動き続けるデータのための基本的なプラットフォームが必要であると、当社は早くから認識していました。古いものをすべて取り替えることなく新しいものを取り入れることができるこの機能は、差別化の重要なポイントであり、多くのお客様のクラウド導入戦略に欠かせない要素となっています。
顧客
2021年3月31日現在、お客様にはフォーチュン500企業のうち136社が含まれ、1~3月の3ヶ月間の収益の約35%を占めました。
2021年3月31日現在、ARRの10万ドル以上の顧客561社(前年374社 +50%)
2021年3月31日現在、ARR100万ドル以上の顧客60社(前年33社 +82%)
収益モデル
提供する製品に適用される収益認識原則に基づいて変化します。
Confluent Platformのサブスクリプションの販売による収益の一部を、期間限定のライセンスが提供された時点で前もって認識しています。
残りの部分は、契約後のカスタマーサポート、メンテナンス、アップグレードを構成し、収益の大部分を占め、サブスクリプション期間にわたって分割して認識しています。
お客様は、Confluent Cloudを最低契約期間なしで利用することができ、これを従量制と呼んでいます。従量制のお客様は、使用量に応じて請求され、収益が計上されます。使用ベースの最低保証契約を結んでいるお客様には、通常、毎年前払いで請求し、お客様の使用状況に応じて収益を認識しています。
こちらのページでCoufluent Cloudの料金シュミレーションが出来ます。
地域・容量・読み込みスピードによって料金が変動します。同プランでも米国内がもっとも安く、米国外でもオーストラリアが最も高く、次いで南アメリカ、アジア、ヨーロッパと安くなっていきます。
競合:Microsoft、Amazon、Google、Tibco software、Cloudera、IBM 、Oracleなど
オンプレミスにおける主な競合は、Apache Kafkaなどのオープンソース・ソフトウェアを使用してデータ・インフラストラクチャ・ソフトウェアを開発する社内のITチーム
クラウドにおける主要な競合は、すべての市場で競争している定評あるパブリッククラウドプロバイダーです。
これらの企業は、完全に管理されたリアルタイム・データ・インジェスチョンおよびデータ・ストリーミング製品を開発し、リリースしています(例:Azure Event Hubs (Microsoft Corporation)、Amazon KinesisおよびAmazon DynamoDB Streams (AWS)、Cloud Pub/SubおよびCloud Dataflow (Google)など、完全に管理されたリアルタイムのデータ取り込みおよびデータストリーミング製品を開発し、リリースしています。オンプレミスでは、TIBCO Streaming、Cloudera Dataflow、Redhat(IBM)、AMQ Streams、Oracle Cloud Infrastructure Streamingなど、レガシー製品を持つ多くのベンダーがこの分野にピボットしています。
リスク要因 Risk factor
リスク要因にはいろいろなことが書かれていますが、個人的に気になった点をいくつか記載します。
リスク要因① 歴史的にConfluent Platformから収益のかなりの部分を得ている傾注リスク
企業向けの自己管理型ソフトウェア製品であるConfluent Platformに大きく依存しています。
Confluent Platformは、2019年12月31日および2020年12月31日に終了した年間のサブスクリプション収益の89%と85%、2020年3月31日および2021年3月31日までの3ヶ月間のサブスクリプション収益の86%と80%をそれぞれ貢献しました。
今後の成長の一部として、Confluent Platformの顧客採用と拡大に頼り続けることを期待しています。
特に、お客様に幅広いユースケースを生成し、既存のお客様とのドルベースの純保持率を高めるために、基本的な自己管理型データ・イン・モーション・オファリングを提供するConfluent Platformに依存しています。市場の受け入れ損失、顧客の更新の減少、新規顧客の採用、Confluent Platformの既存顧客間のユースケースの拡大が制限された場合、当社の成長、ビジネス、財務状況、および業績が損なわれる可能性があります。
リスク要因②期間に応じて業績が変動しうるリスク
利用パターンやプラットフォームの収益認識時期による売上変動リスク、今は売り上げの小さいCoufluent Cloudの売上増加によるインフラコスト上昇=利益率の変動があり得ます。(先ほど収益モデルについての記載部分と重複あります。)
Confluent Platformのサブスクリプションの販売による収益の一部を、期間限定のライセンスが提供された時点で前もって認識しています。
残りの部分は、契約後のカスタマーサポート、メンテナンス、アップグレードを構成し、収益の大部分を占め、サブスクリプション期間にわたって分割して認識しています。
お客様は、Confluent Cloudを最低契約期間なしで利用することができ、これを従量制と呼んでいます。従量制のお客様は、使用量に応じて請求され、収益が計上されます。使用ベースの最低保証契約を結んでいるお客様には、通常、毎年前払いで請求し、お客様の使用状況に応じて収益を認識しています。
歴史的に、Confluent Cloudの売上は個別に小さく、そのような顧客の使用レベルは時間とともに変化してきましたが、Confluent Cloudの販売戦略の一環として商用顧客セグメントをターゲットにしているため、この傾向が続く可能性があります。
その結果、収益は顧客の利用パターンやConfluent Platformの販売時期に左右されるため、期間限定ライセンスの提供時に多額の前払い収益を認識することになり、期間ごとに収益が変動する可能性があります。また、Confluent Cloudの売上増加に伴うクラウドインフラコストの上昇により、利益率が変動する可能性があります。今後、収益構成のさらなる変化などにより、期間をまたいだ収益や業績の変動が生じた場合、当社の将来の成長や業績を評価することが困難になる可能性があります。
S-1をみて、個人的に気になった点
技術的に理解が難しかったです。使ったわけでは無いので実際便利なのかというのはエンジニア部門やIT部門の人にしかなかなかわからず、文系の私にはほぼ何もわからなかったです。
技術的な部分は他のサイトなどをみて理解を進めましたが、世の中に受け入れられているのかどうか、利益が出せるかどうか、などの懸念はすべて数字が物語ると思いますので、今後数字を見ていきたいと思いました。

決算
2021年Q2 良い決算
🧑💻 $CFLT Confluent FY21 Q2
— ユーエスさん🇺🇸米国株投資🍺🥃🍷🍶⚽ (@us_stock_invest) August 6, 2021
⭕️EPS: -$0.31🆚-$0.39
⭕️売上高: $88.3M(+64%)🆚$76.86M
▶️Highlights
Confluent Cloud: $20M(+200%)
RPO: $327.2M(+72%)
ARR $100K超 顧客: 617(+51%)
▶️ガイダンス
Q3
EPS: -$0.24~-0.23
売上高: $89~91M
FY21
EPS: -$1.07~-1.05
売上高: $347~351M
▶️時間外 +7%📈
2021年Q3 良い決算
コンフルエント$CFLT
— 𝐓🇺🇸投資勉強中 (@dangerousteee) November 4, 2021
Q3
EPS予想-$0.23 結果-$0.17
売上高予想 $90.72M 結果$102.6M (+66.8% Y/Y)
Q4
売上高予想$95.04M 新ガイダンス$108-$110M
EPS予想-$0.25 新-$0.23~-$0.21
FY2021
売上高予想$352.40M 新ガイダンス$376-$378M
EPS予想-$1.02 新-$0.92~-$0.9


コメント